
Actualmente, resulta muy interesante conocer cómo funciona el proceso de creación de una página web. Aunque podemos inicialmente trabajarla en local, al final siempre va a ser necesario contratar hosting con dominio. Para crear tu web, vas a necesitar además contar con una base de datos. Si no tienes ni idea de lo que es, en este post te lo explicamos y te enseñamos a crear una.
Qué es una base de datos MySQL y cómo puedo crear una: la guía definitiva
TABLA DE CONTENIDOS
Del mismo modo, en el entorno corporativo es de gran interés saber crear una base de datos en MySQL, uno de los sistemas más populares del mundo en la actualidad. Y es que las bases de datos son ampliamente utilizadas en el mundo empresarial, para la creación de, por ejemplo, un sistema en el que registrar y almacenar datos relativos a los clientes o a los productos.
A continuación explicamos qué es una base de datos, así como las características relativas a MySQL. Del mismo modo, explicamos la creación de una base de datos MySQL paso a paso.
¿Qué es una base de datos?
Una base de datos se define como un conjunto de datos organizados, los cuales guardan una cierta relación entre sí. Así, los sistemas de información se encargan de recolectarlos y, posteriormente, gestionarlos y administrarlos para unos objetivos concretos. Las bases de datos tienen una serie de características que resulta interesante conocer.
Desde el lado de la informática, la base de datos se conoce como un sistema conformado por un abanico de datos almacenados en distintos discos, físicos o virtuales, que permiten el acceso directo a los mismos y un software capaz de manipular dichos datos.
Cada base de datos se compone e una o varias tablas, las cuales guardan un grupo de datos. Cada tabla se conforma de una o más columnas y filas. De este modo, cada columna almacena una parte de la información acerca de cada elemento que se desee guardar en la tabla, mientras que cada fila de la tabla compone un registro.
Por un lado, todos los datos almacenados guardan una independencia tanto lógica como mínima. Además, todos ellos tienen una redundancia mínima.
Por otro lado, uno o varios usuarios pueden tener acceso a los datos almacenados en la base mediante un acceso seguro.

Bases de datos en MySql
MySQL es un sistema de gestión de base de datos que actualmente cuenta con más de seis millones de clientes en todo el mundo. Un software libre que se engloba en el grupo de licencias GNU GPL. MySQL es a día de hoy ampliamente utilizado en una gran selección de aplicaciones web tales como WordPress o Drupal, entre otras. Una de sus principales ventajas es que su lectura es muy rápida, por lo que es una opción estupenda para este tipo de apps.
A continuación señalamos las principales características que definen las bases de datos MySQL.
- Arquitectura cliente y servidor: MySQL, al igual que cualquier otro sistema de registros de datos, es un programa de registro basado en un sistema entre cliente y servidor. Se trata por tanto de un software en el que se engloban un amplio abanico de clientes y servidores que establecen comunicación entre ellos.
- Compatibilidad con SQL: SQL es un lenguaje de programación que permite tanto la consulta como la renovación de datos para la gestión de una base en la que se almacena un conjunto de datos.
- Búsqueda de texto completo: la búsqueda de texto completo acelera y facilita en gran medida el sistema de búsqueda de las palabras de los datos contenidos en la base.
- Lenguaje de programación: la base de datos MySQL está escrita en C y C++, dos de los lenguajes de programación más demandados y populares de todo el mundo.
- Sistemas de almacenamiento: este tipo de bases proporciona sistemas de almacenamiento tanto transaccionales como no transaccionales.
Cómo crear una base de datos paso a paso
Crear base de datos MySQL es un proceso relativamente sencillo, por lo que no se necesitan conocimientos técnicos avanzados para realizarlo. A continuación explicamos paso a paso cómo crear una base de datos en MySQL.
- En primer lugar es importante asegurarse de que el servidor MySQL está conectado. De lo contrario, la creación de la base de datos es imposible.
- A continuación se copia la ruta de instalación de la carpeta. Dicha ruta puede variar en función de si se va a hacer uso de Windows o Mac. En caso de Windows, se copia:
Si el SO es iOS, se copia:C:/Program Files/MySQL/MySQL Workbench 8.0 CE//usr/local/mysql-8.0.13-osx10.13-x86_64/ - El siguiente paso consiste en abrir la línea de comandos del ordenador. En un PC se abre “Símbolo del Sistema”. En caso de Mac, “Terminal”.
- Ahora es el momento de crear el archivo de la base de datos. Para ello, se escribe el comando de creación de base de datos:
y se le agrega el nombre que se le quiera asignar, seguido de un punto y coma. Por último, se pulsa “Enter”. Por ejemplo si la base de datos se quiere denominar “Registro de clientes”, tendrás que escribir:create database
Create Database Registro_de_clientes
Una vez creada la base de datos, es el momento de crear una tabla.
En primer lugar se crea la estructura de la propia tabla. El comando es el siguiente.
CREATE TABLE nombre (columna1 VARCHAR(20), columna2)CREATE TABLE Registro de clientes (Lugar de residencia VARCHAR(20), Edad VARCHAR(30),INSERT INTO Registro de clientes VALUES ('Madrid', '30');show databases;select * from nombreCrear una base de datos desde Plesk
Si tienes un hosting con panel de control Plesk, puedes crear una base de datos de una forma mucho más visual y usando la herramienta phpMyAdmin. Para esto sólo tienes que acceder al área de cliente en Axarnet.es, con tus datos de acceso.
Una vez estés dentro, sólo tienes que seleccionar la suscripción en la que quieras crear la base de datos y en seguida verás la opción de Base de datos.
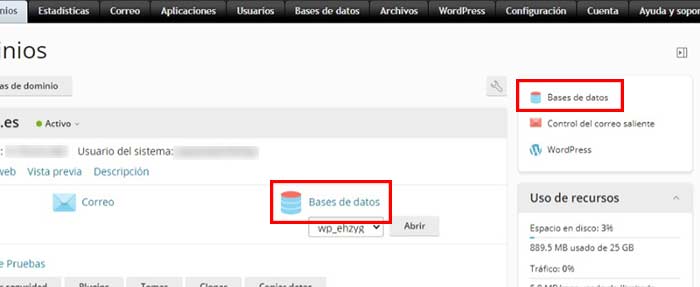
En cuanto accedas verás las bases de datos que ya están creadas y esas no tienes que modificarlas. Si quieres una base de datos nueva, utiliza el botón de Añadir base de datos. En la siguiente pantalla tendrás que añadir los datos de la base de datos, no el contenido, que lo harás más tarde con phpMyAdmin. Aquí tendrás que añadir:
- Nombre de la base de datos
- Nombre de usuario de la base de datos
- Contraseña
También puedes elegir si quieres relacionarlo con algún sitio que tengas creado en la suscripción. Si sólo tienes uno, no tendrás que elegir nada.
El nombre de usuario y la contraseña son necesarios para poder crear la base de datos y si luego quieres conectarla con alguna aplicación, tendrás que usar las credenciales. Una vez tengas los datos añadidos, sólo tienes que pulsar en Aceptar y la base de datos se creará en seguida.
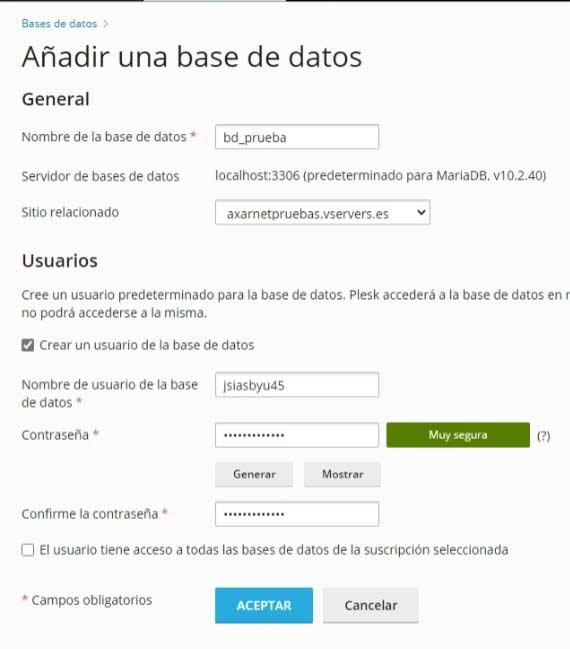
Cuando se haya creado la base de datos el sistema te llevará de vuelta al punto anterior y verás que tienes las opciones disponibles en tu nueva base de datos. En la esquina superior derecha verás un botón de phpMyAdmin y un icono con su logotipo. Cualquier de las dos opciones te llevará a phpMyAdmin.
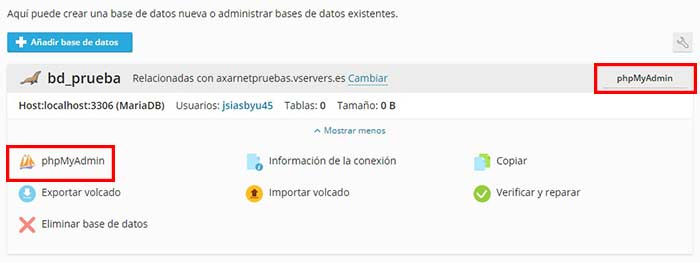
Una vez dentro de la herramienta, verás que tienes todas las opciones que necesitas para darle forma a la base de datos, puedes crear tablas, añadir valores o incluso importar los datos de otra base de datos que tengas en tu ordenador.
Al tener la base de datos ya creada en el hosting la puedes usar en cualquier aplicación que soporte MySQL y trabajar con ella desde el principio y en tiempo real.
Herramientas para trabajar con MySQL
Trabajar con bases de datos MySQL puede ser mucho más eficiente y amigable con el uso de herramientas adecuadas que faciliten la gestión, diseño y consulta de datos.
Aquí tienes algunas de las herramienta más utilizadas para gestionar y trabajar con bases de datos MySQL:
-
- Gestión y Administración: Proporciona un conjunto de herramientas para la administración de la configuración de MySQL, la gestión de usuarios y la monitorización del rendimiento.
- Diseño de Bases de Datos: Permite diseñar y modelar bases de datos de manera visual, facilitando la creación y modificación de esquemas.
- Desarrollo de SQL: Ofrece un editor SQL avanzado para escribir, ejecutar y depurar consultas SQL.
-
- Soporte Multi-DBMS: Además de MySQL, soporta una variedad de sistemas de gestión de bases de datos como PostgreSQL, SQL Server, Oracle, entre otros.
- Herramientas de Análisis de Datos: Proporciona herramientas para analizar y visualizar datos, facilitando la comprensión de los datos almacenados.
- Importación/Exportación de Datos: Facilita la migración de datos entre diferentes bases de datos y formatos de archivo.
-
- Editor Inteligente: Ofrece un editor de código SQL inteligente que proporciona resaltado de sintaxis, autocompletado y análisis de código en tiempo real.
- Navegación y Búsqueda Efectiva: Permite navegar a través de la estructura de la base de datos y buscar datos de manera eficiente.
- Soporte para Varios DBMS: Al igual que DBeaver, DataGrip soporta múltiples sistemas de gestión de bases de datos, lo que la hace una herramienta versátil para entornos heterogéneos.
Seguridad en MySQL
La seguridad en MySQL es algo fundamental para asegurar la integridad, confidencialidad y disponibilidad de tus datos. Aquí te dejo algunos puntos cruciales a tener en cuenta, acompañados de ejemplos prácticos:
- Gestión de Usuarios y Privilegios: Es esencial limitar los privilegios de los usuarios según sus necesidades específicas. No todos los usuarios necesitan acceso total. Por ejemplo, para crear un usuario con acceso limitado, podrías usar:
sqlCopy codeCREATE USER 'usuario_seguro'@'localhost' IDENTIFIED BY 'contraseña_segura';
GRANT SELECT, INSERT, UPDATE ON tu_base_de_datos.* TO 'usuario_seguro'@'localhost';
- Cifrado de Datos: Protege los datos sensibles utilizando cifrado tanto en reposo como en tránsito. MySQL ofrece cifrado de datos en reposo con
InnoDB tablespace encryptiony cifrado en tránsito mediante SSL/TLS. - Políticas de Contraseñas Robustas: Implementa políticas de contraseñas fuertes para todos los usuarios de la base de datos. MySQL facilita esto a través de su plugin de validación de contraseñas.
- Auditoría y Monitoreo: Realiza auditorías periódicas y monitorea los logs de acceso y errores para detectar actividades sospechosas. Herramientas como MySQL Enterprise Audit facilitan este proceso.
Las medidas puede ayudarte a fortalecer la seguridad de tu base de datos MySQL, creando un entorno más seguro para tus datos.
Integración con otras aplicaciones
La flexibilidad de MySQL le permite integrarse sin problemas con muchas aplicaciones, siendo WordPress y PrestaShop dos ejemplos muy populares de sistemas que usarn MySQL y que demuestran su versatilidad.
- WordPress: Este sistema de gestión de contenidos es el compañero perfecto para MySQL. La integración de MySQL con WordPress permite a los usuarios disfrutar de una experiencia de gestión web perfecta. Sin MySQL, WordPress no sería lo mismo.
- PrestaShop: En el mundo del comercio electrónico, PrestaShop se destaca por su facilidad de uso y eficiencia, algo que no sería posible sin la base de datos que MySQL proporciona. Juntos, facilitan la gestión de inventarios, clientes y transacciones, haciendo que la administración de tu tienda en línea sea pan comido.
Conclusiones
A lo largo de este post, hemos navegado juntos por el mundo de las bases de datos, poniendo un foco especial en MySQL, una herramienta clave en el desarrollo web y en la gestión de datos.
Te he guiado paso a paso para crear tu propia base de datos en MySQL tanto manualmente como a través de Plesk, facilitando tu incursión en esta área vital.
Además, te presenté compañeros de viaje útiles como MySQL Workbench, DBeaver y DataGrip, que harán tu travesía por la gestión de bases de datos mucho más sencilla y enriquecedora.

Hosting Web

Dominios
El primer paso de un negocio en Internet es contar con un dominio. ¡Regístralo!
Certificado SSL
Protege tu web, gana posiciones en Google y aumenta tus ventas y clientes.

